What is Machine Learning
Informally, an algorithm is any well-defined computational procedure that takes some value, or set of values, as input and produces some values, or set of values, as output. An algorithm is thus a sequence of computational steps that transform the input into the output.
Mimic Outputs, Not The Process
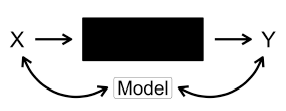
In the context of prediction, nature can be seen as a mechanism that takes features \(X\) and produces output \(Y\) . This mechanism is unknown, and modelers “fill” the gap with models.

Statistical modelers fill this box with a statistical model. If the modeler is convinced that the model represents the data-generating process well, they can interpret the model and parameters as parameters of nature. Since nature’s true mechanism is unknown and not fully specified by the data, modelers have to make some assumptions.

Type of Learning
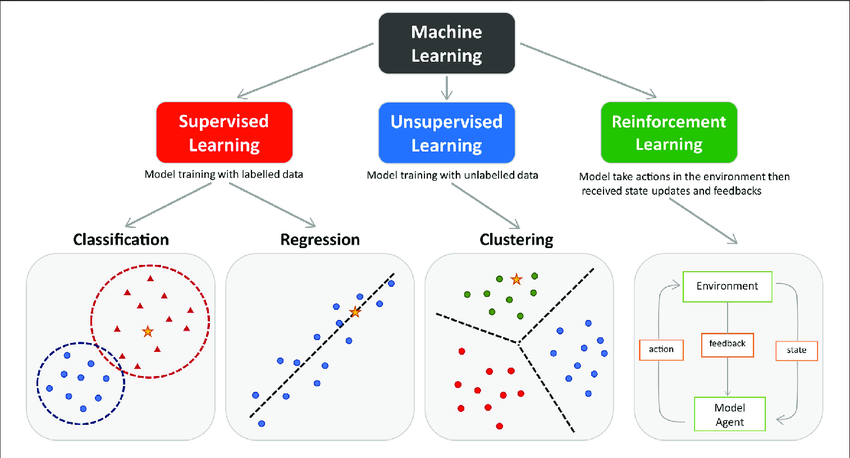
Supervised Learning
In supervised learning, nature is seen as unknowable. Instead of the intrinsic approach, supervised learning takes an extrinsic approach. The supervised model is supposed to mimic the outputs of nature, but it doesn’t matter whether the model’s inner mechanism is a reasonable substitute for nature’s mechanism.
A statistical modeler would try to find a plausible recipe, even if the end result is not perfect. The supervised learner would only be interested in the end result; it doesn’t matter whether it was exactly the same recipe.
Is to map input onto sets of output, which had been pre-determined by the “supervisor” or researcher/analyzer/modeler. Hence called “supervised”. The problem is \(X \mapsto Y\). In another word, we have \(X\) as input space, and \(Y\) output space, and the learning is a process of mapping from \(X\) to \(Y\). The learner receives a set of labeled examples as training data and makes predictions for all unseen points.
Regression
The goal of regression is to predict the value of one or more continuous target variables \(t\) given the value of a D-dimensional vector \(x\) of input variables. Usually, predict a numerical value.
Given a training data set comprising \(N\) observations \(\{x_n \}\), where \(n = 1, . . . , N ,\) together with corresponding target values \(\{t_n\}\), the goal is to predict the value of \(t\) for a new value of \(x\).
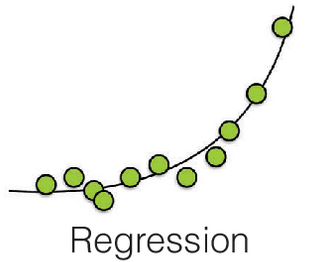
Example:
- What will the temperature for tomorrow morning?
- What is Kelana Park View apartment current selling prices?
- predict water temperature based on salinity
- predict the apparent temperature given the humidity
- stock price predict of Tesla Inc
Types of Regression Algorithm:
- Simple Linear Regression
Classification
The goal in classification is to take an input vector \(x\) and to assign it to one of \(K\) discrete classes \(\{C_k \}\) where \(k = 1, . . . , K\). In the most common scenario, the classes are taken to be disjoint, so that each input is assigned to one and only one class. The input space is thereby divided into decision regions whose boundaries are called decision boundaries. Classify into two or multiple classes.
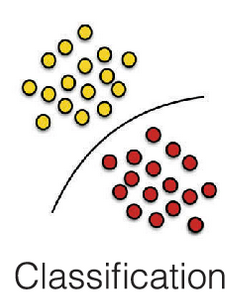
Examples:
- Tomorrow morning raining or sunny?
- Image classification
- Document classification
- Facial/Voice recognition
- Text classification
Types of Classification Algorithm:
- Neural network
- support vector machine
- Naive Bayes
- K-Nearest Neighbors
- Decision Tree Classifier
- Random Forest Classifier
With the rapid development of data collection and storage technologies, we have entered the era of big data, where the data holds a trend of rapid growth in both sample size and feature dimensionality.
As we add more dimensions(features) to our dataset, the volume of the space increases exponentially. This means that the data becomes sparse.
This sparsity making it hard to find patterns or relationships (lack of representativeness). It also will increase computation cost.
Unsupervised learning
Unsupervised learning means discovering hidden patterns in data. Unsupervised learning is more like, “Here are some data points. Please find something interesting.” The learner exclusively receives unlabeled training data, and makes predictions for all unseen points.
We have only \(Xs\), input data, and no output to map to. \(Y\) may exist, but it is “latent” (i.e. not directly observable)
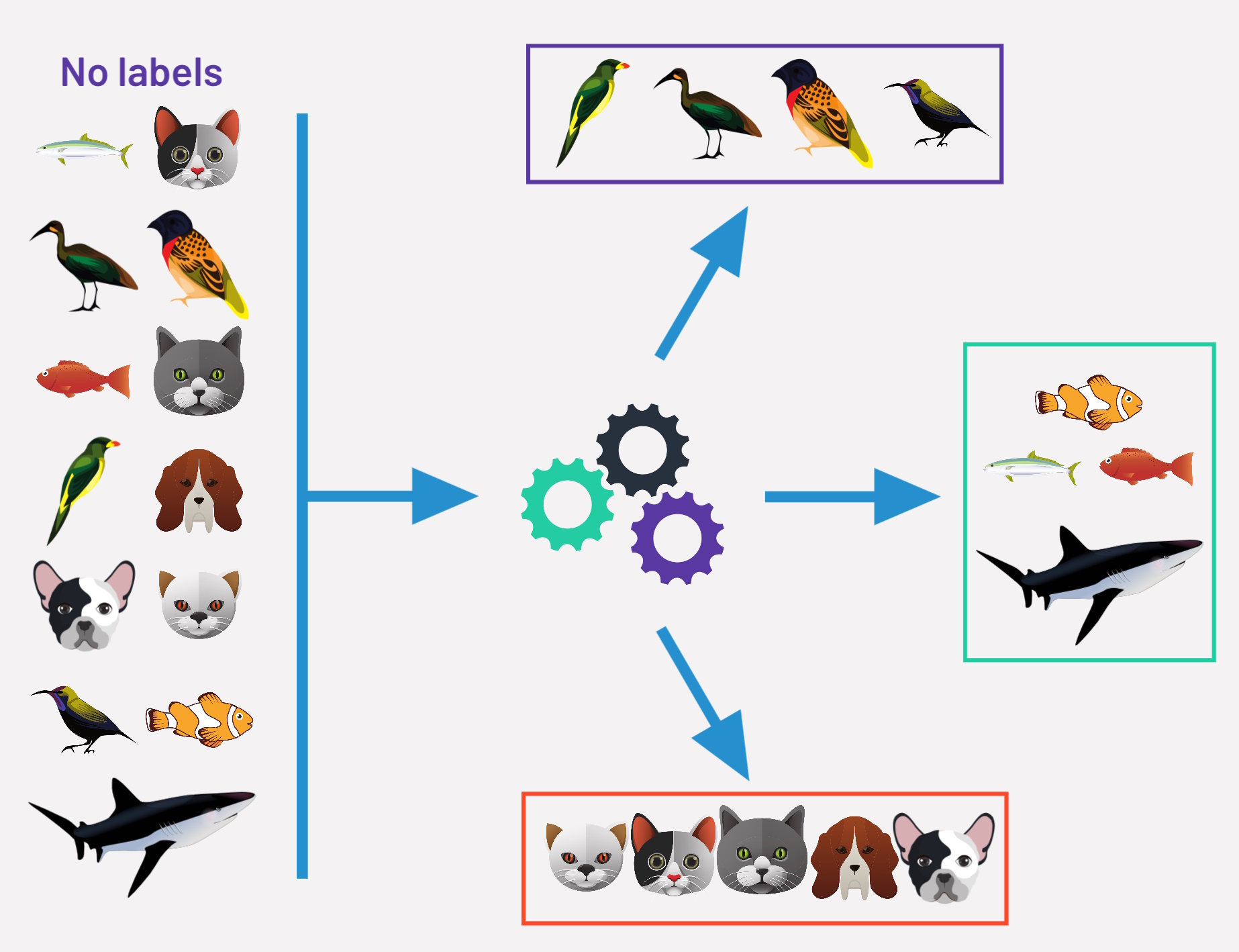
Examples:
- anomaly detection
- customer segmentation
Reinforcement Learning
Reinforcement learning is dynamic learning.
The output \(Y\) is a set of actions, which is ordered in a sequence \((A_i,A_j,A_k,...,A_n)\). The objective is to “learn” which set of actions sequence which maximizes the rewards, \(R\). \(S\) now is called the possible states or set of states. \(Y\) is the game theoretic action space choosing the states, and \(Z\) is the reward space, given various state space sequences or paths.
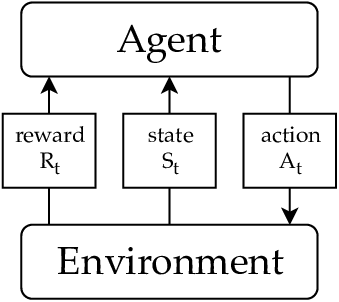
Examples:
- self-driving cars
- industrial robotics
- chatGPT
Example Session
Session with python and relevant libraries.
Interpretability vs flexibility
A popular definition of interpretability frequently used by researchers is “interpretability in machine learning is a degree to which a human can understand the cause of a decision from an ML model”. It can also be defined as “the ability to explain the model outcome in understandable ways to a human. So far, no mathematical definition. The primary goal of interpretability is to explain the model outcomes in a way that is easy for users to understand.
Interpretability — If a business wants high model transparency and wants to understand exactly why and how the model is generating predictions, they need to observe the inner mechanics of the AI/ML method. This leads to interpreting the model’s weights and features to determine the given output. This is interpretability.
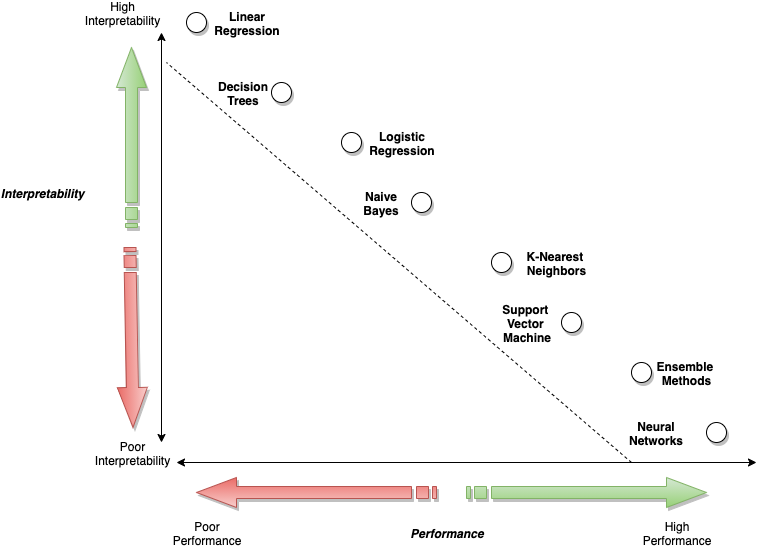
High interpretability typically comes at the cost of performance, as seen in the following figure. If we wants to achieve high performance but still wants to have a general understanding of the model behavior, model explainability starts to play a larger role.
Explainability — Explainability is how to take an ML model and explain the behavior in human terms.
When datasets are large and the data is related to images or text, neural networks can meet the customer’s AI/ML objective with high performance. In such cases, where complex methods are required to maximize performance, data scientists may focus on model explainability instead of interpretability.
Flexibility — There’s no rigor definition of method’s flexibility. Flexibility describes the ability to increase the degrees of freedom available to the model to “fit” to the training data.